Task-relevant Autonomy: The robot needs to collect data with high signal to noise ratio, to learn more efficiently. We use an auto-grap procedure which uses segmentation models to identify objects of interest and grasp them before running the neural policy. Further we use goal cycles and/or multiple robots to automate resets for continual learning.
Approach Overview
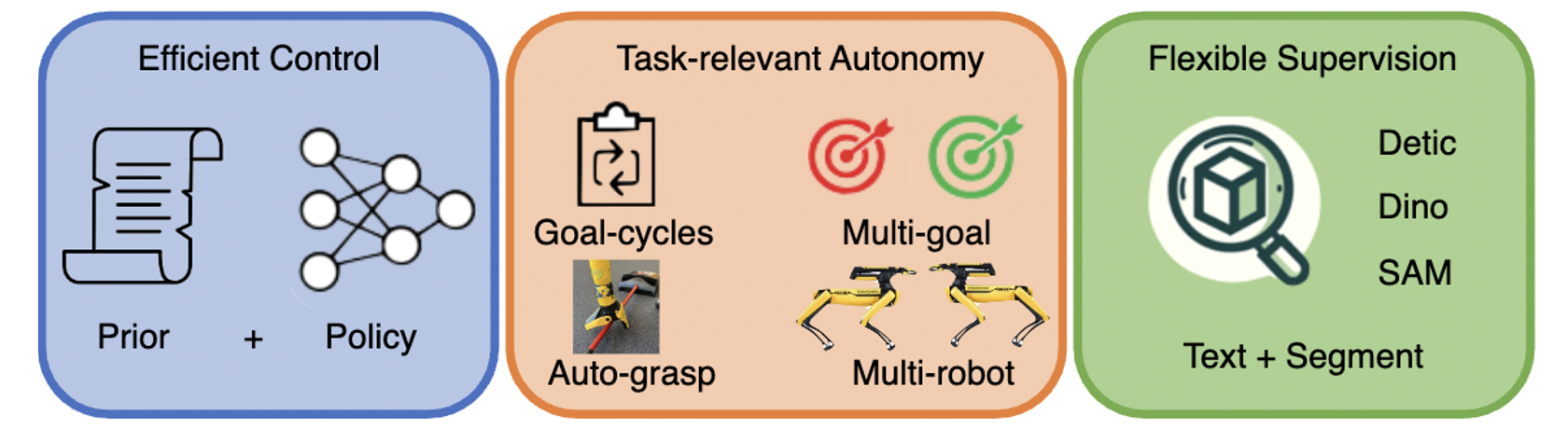
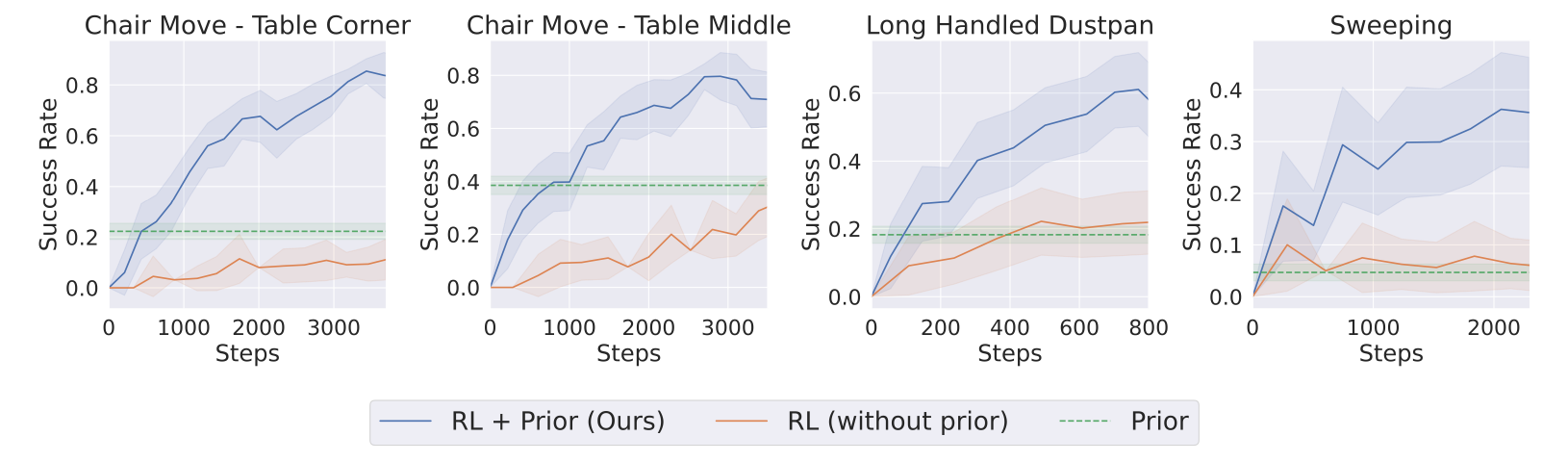
Efficient Control: We combine a neural controller along with priors, which can take the form of planners with simplified models or simple scripts that generate suboptimal behavior. Neural policy learning is driven by model-free RL using Q learning by sampling data from both the online policy and prior.
Flexible Supervision: We use language-guided detection models and vision segmentation models to identify objects of interest. We combine this with low-level depth observations for state estimation, which is used to specify rewards.